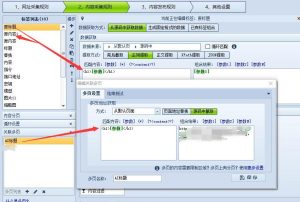
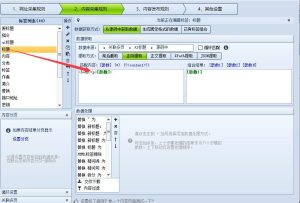
当我们用火车头采集器采集标题时,如果要实现双标题,比如原标题+百度下拉词或其他词,这种组合的标题有可能会有重复的部分,
比如标题:适合五一出游的地方 适合五一出游的地方推荐
那么如何实现自动去重呢?
先说结论,直接上代码:
// 双标题去重 双标题是用空格隔开
using System;
using System.Collections.Generic;
using SpiderInterface;
class LocoyCode {
public string Run(string content, ResponseEntry response) {
string[] words = content.Split(new char[] { ' ' }, StringSplitOptions.RemoveEmptyEntries);
Dictionary<string, int> uniqueWords = new Dictionary<string, int>();
foreach (string word in words) {
if (!uniqueWords.ContainsKey(word)) {
uniqueWords.Add(word, 1);
} else {
uniqueWords[word]++;
}
}
bool hasDuplicate = false;
for (int i = 0; i < words.Length; i++) {
for (int j = i + 1; j < words.Length; j++) {
if (words[i].Contains(words[j]) || words[j].Contains(words[i])) {
hasDuplicate = true;
break;
}
}
if (hasDuplicate) {
break;
}
}
if (hasDuplicate) {
string result = "";
foreach (KeyValuePair<string, int> pair in uniqueWords) {
if (pair.Value == 1) {
result = pair.Key;
} else if (result.Length < pair.Key.Length) {
result = pair.Key;
}
}
return result;
} else {
return content;
}
}
}比如标题:适合五一出游的地方 适合五一出游的地方推荐,处理后就得到:适合五一出游的地方推荐。
![图片[1]-火车头采集器通过脚本轻松实现双标题内容去重-SEO模板](https://www.seomoban.cn/wp-content/uploads/2025/11/双标题去重-300x211.jpg)
火车头C#脚本:双标题去重 详细说明
一、 脚本功能概述
该脚本的核心功能是处理由空格分隔的“双标题”或“多标题”字符串。它的目标是:
- 检测重复:判断标题中的各个部分是否存在包含关系(例如,“中国”和“中国历史”被视为重复)。
- 智能去重:如果检测到重复,脚本会从所有标题部分中,挑选出最合适的一个作为最终结果。
- 保留原样:如果标题各部分之间没有任何包含关系,则直接返回原始标题。
二、 脚本工作原理详解
让我们分步解析代码的执行逻辑: 输入示例: content = "中国历史 世界历史"
第一步:分词
string[] words = content.Split(new char[] { ' ' }, StringSplitOptions.RemoveEmptyEntries);
- 作用:使用空格
作为分隔符,将输入的字符串content切割成一个字符串数组words。 StringSplitOptions.RemoveEmptyEntries确保即使有多个连续空格,也不会产生空字符串。- 示例结果:
words数组变为["中国历史", "世界历史"]
第二步:统计词频
Dictionary<string, int> uniqueWords = new Dictionary<string, int>();
foreach (string word in words) {
if (!uniqueWords.ContainsKey(word)) {
uniqueWords.Add(word, 1);
} else {
uniqueWords[word]++;
}
}
- 作用:遍历
words数组,使用一个字典uniqueWords来记录每个独立标题部分出现的次数。 - 注意:对于“双标题”场景,通常每个部分都是唯一的,所以这个字典里的
Value大部分时候是1。但如果输入是"中国 中国历史",那么uniqueWords会是{"中国": 2, "中国历史": 1}。 - 示例结果:
uniqueWords字典为{"中国历史": 1, "世界历史": 1}
第三步:检测包含关系(核心逻辑)
bool hasDuplicate = false;
for (int i = 0; i < words.Length; i++) {
for (int j = i + 1; j < words.Length; j++) {
if (words[i].Contains(words[j]) || words[j].Contains(words[i])) {
hasDuplicate = true;
break;
}
}
if (hasDuplicate) {
break;
}
}
- 作用:这是判断是否需要去重的关键。它使用双重循环,比较数组中任意两个不同的词。
words[i].Contains(words[j])检查words[i]是否包含words[j]。words[j].Contains(words[i])检查words[j]是否包含words[i]。- 只要找到任何一对词满足包含关系,
hasDuplicate标志就会被设为true,并立即跳出循环。 - 示例分析:
words[0]是 “中国历史”,words[1]是 “世界历史”。"中国历史".Contains("世界历史")为false。"世界历史".Contains("中国历史")为false。- 循环结束,
hasDuplicate保持为false。
第四步:根据检测结果返回结果
if (hasDuplicate) {
// ... 逻辑A ...
} else {
return content;
}
- 情况一:没有包含关系 (
hasDuplicate为false)- 直接执行
else分支,返回原始内容content。 - 示例: 返回
"中国历史 世界历史"。
- 直接执行
- 情况二:存在包含关系 (
hasDuplicate为true)- 执行
if分支内的逻辑A。
- 执行
第五步:当存在重复时,选择最佳标题(逻辑A)
string result = "";
foreach (KeyValuePair<string, int> pair in uniqueWords) {
if (pair.Value == 1) {
result = pair.Key;
} else if (result.Length < pair.Key.Length) {
result = pair.Key;
}
}
return result;
- 作用:遍历之前统计的词频字典
uniqueWords,目的是找出一个“最佳”标题。 - 选择规则:
- 优先选择出现次数为1的词:
if (pair.Value == 1)。这个逻辑在处理"中国 中国历史"时,会先选择"中国历史"(因为它的Value是1),然后遇到"中国"(Value是2)时,不会更新result。最终保留"中国历史"。 - 在出现次数都为1的情况下,选择最长的词:
else if (result.Length < pair.Key.Length)。如果所有词都只出现了一次,这个规则会确保最终保留的是信息量最全、最长的那个标题。
- 优先选择出现次数为1的词:
- 示例: 假设输入是
"中国 中国历史"hasDuplicate会变为true。uniqueWords是{"中国": 2, "中国历史": 1}。foreach循环开始:- 遇到
{"中国": 2},不满足pair.Value == 1,跳过。 - 遇到
{"中国历史": 1},满足pair.Value == 1,result被赋值为"中国历史"。
- 遇到
- 循环结束,返回
result,即"中国历史"。
三、 使用说明
- 适用场景:
- 采集的标题字段中,包含由单个或多个空格分隔的两个或多个标题片段。
- 这些片段中,通常一个是另一个的子集,例如
"北京 北京天气预报"或"手机评测 苹果14Pro深度评测"。
- 在火车头中的配置:
- 位置:将此脚本放在“内容处理规则”或“标签处理”中的 C#处理 插件里。
- 变量:脚本中的
content变量会自动接收传入的标签内容(例如,[标签:标题]的值)。你不需要修改这部分。 - 返回值:脚本的
return值将作为处理后的新内容,替换掉原始标签内容。
- 使用示例:
输入内容 ( content)脚本执行过程 输出结果 "中国历史 世界历史"无包含关系, hasDuplicate为false"中国历史 世界历史""中国 中国历史""中国"被"中国历史"包含,hasDuplicate为true。选择更长的"中国历史""中国历史""手机评测 苹果14Pro深度评测""手机评测"被"苹果14Pro深度评测"包含(不,这个例子不包含,脚本会保留原样)。一个更好的例子是:"评测 苹果14Pro深度评测""苹果14Pro深度评测""天气预报 天气""天气"被"天气预报"包含,hasDuplicate为true。选择更长的"天气预报""天气预报""A B C"任意两词之间均无包含关系 "A B C"
四、 优缺点分析
优点
- 目标明确:脚本非常专注于解决“包含关系”的标题去重问题,对于这类场景效果直接。
- 逻辑清晰:代码结构简单,易于理解和修改。即使不熟悉C#的开发者也能看懂其核心逻辑。
- 智能选择:当存在重复时,它不是简单地删除一个,而是通过“选择最长”的策略,保留了信息最完整、最具体的标题,这是一个很实用的优点。
- 兼容性好:基于.NET Framework的C#代码,在火车头采集器中运行稳定,无需额外依赖。
缺点
- 性能问题(双重循环):
- 检测包含关系的部分使用了双重
for循环。其时间复杂度为 O(n²)。 - 对于标题片段非常多的情况(例如,由空格隔开的10个词),性能会显著下降。但对于“双标题”这种片段数量很少(通常2-3个)的场景,这个缺点几乎可以忽略不计。
- 检测包含关系的部分使用了双重
- 匹配规则过于严格:
- 脚本使用
string.Contains(),这是大小写敏感且严格匹配的。 - 无法处理同义词:例如,
"中国历史"和"中华上下五千年",虽然意思相近,但不存在字符串包含关系,脚本无法识别。 - 无法处理细微差异:例如,
"苹果14 Pro评测"和"苹果14Pro评测",由于缺少空格,Contains也会失败。
- 脚本使用
- 对分隔符的硬编码:
- 脚本硬编码使用空格
作为分隔符。如果原始数据使用其他分隔符(如-、|、/),脚本将无法正确分词,导致失效。
- 脚本硬编码使用空格
- 词频统计逻辑略显冗余:
- 在典型的“双标题”场景下,每个片段通常只出现一次,词频统计部分
uniqueWords的主要作用其实是为了遍历所有唯一的词。虽然逻辑上可行,但可以写得更简洁(例如直接遍历words数组并去重)。
- 在典型的“双标题”场景下,每个片段通常只出现一次,词频统计部分
五、 总结与建议
这个脚本是一个小巧、实用的“小工具”,非常适合解决火车头采集中常见的、格式固定的“双标题包含”问题。它的优点在于简单直接,选择策略智能。 使用建议:
- 放心使用:如果你的数据格式稳定(总是空格分隔,且存在明确的包含关系),这个脚本非常可靠。
- 注意数据清洗:在使用此脚本前,最好确保标题字段中没有多余的、不必要的空格。
- 考虑扩展:如果你的数据格式更复杂(例如,使用多种分隔符),可以考虑修改
Split部分,使其能处理多种情况。例如:// 修改后的分词代码,支持多种分隔符 char[] separators = new char[] { ' ', '-', '|', '/' }; string[] words = content.Split(separators, StringSplitOptions.RemoveEmptyEntries);
总的来说,这是一个在特定场景下表现出色的脚本,理解其工作原理和局限性后,可以更有效地发挥它的价值。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
THE END