查找所有的 <h2> 或 <h3> 标签,并为它们统一、连续地添加带编号的 span 锚点。
先给对应的 C# 代码:
//将内容中所有的h2或h3标签,添加span并顺序编号,成为li内容导航的锚点
using System;
using System.Collections.Generic;
using System.Text.RegularExpressions;
using SpiderInterface;
class LocoyCode
{
public string Run(string content, ResponseEntry response)
{
// 使用正则表达式查找所有的<h2>或<h3>标签
// 修改点:将 <h2> 改为 <h(2|3)>,并使用 RegexOptions.IgnoreCase 以兼容大小写
var regex = new Regex(@"<h(2|3)>(.*?)</h\1>", RegexOptions.IgnoreCase | RegexOptions.Singleline);
int count = 1;
// 使用MatchEvaluator委托进行匹配项的处理
string resultContent = regex.Replace(content, match =>
{
// 获取匹配到的完整标签,例如 "<h2>标题</h2>"
string fullTag = match.Value;
// 从完整标签中提取出开头的标签名,例如 "h2" 或 "h3"
// match.Groups[1].Value 对应正则中的 (2|3)
string tagType = "h" + match.Groups[1].Value;
// 提取标签内的文本内容
string tagContent = match.Groups[2].Value;
// 构造新的<h2>或<h3>标签,其中包含编号的<span>
string newTag = "<" + tagType + "><span name=\"" + count + "\" id=\"" + count + "\"></span>" + tagContent + "</" + tagType + ">";
count++; // 更新编号
return newTag;
});
return resultContent;
}
}
代码说明:
- 正则表达式修改:
- 正则:
@"<h(2|3)>(.*?)</h\1>" h(2|3):这部分会匹配h2或h3。括号()创建了一个捕获组,我们可以在后续代码中引用它。</h\1>:\1是一个反向引用,它会引用第一个捕获组(2|3)匹配到的内容。如果开头是<h2>,这里就会匹配</h2>;如果开头是<h3>,这里就会匹配</h3>。这确保了开始和结束标签的配对。RegexOptions.IgnoreCase:添加了这个选项,使得正则表达式可以匹配<H2>、<h3>等大小写混合的标签,增强了代码的健壮性。
- 正则:
- 标签重建逻辑:
match.Groups[1].Value:获取第一个捕获组的内容,即2或3。string tagType = "h" + match.Groups[1].Value;:通过拼接,我们得到了完整的标签名h2或h3。string newTag = "<" + tagType + "..." + "</" + tagType + ">";:使用动态获取的tagType来构建新的开始和结束标签,确保无论是 h2 还是 h3 都能被正确处理。
- 编号逻辑:
count变量在MatchEvaluator委托外部定义,并在每次匹配成功后递增。这意味着<h2>和<h3>标签会共享同一个连续的编号序列(例如,第一个 h2 是 1,第一个 h3 是 2,第二个 h2 是 3,以此类推)。 这个修改后的版本完全符合您的要求,能够统一处理<h2>和<h3>标签,并为它们生成连续的导航锚点。
效果

使用说明
1. 功能概述
本C#插件是为火车采集器设计的一个内容处理脚本。它的核心功能是:
- 自动扫描文章内容中的所有
<h2>和<h3>标签。 - 顺序编号:为每一个找到的标题标签分配一个从1开始的连续数字编号(例如,第一个标题是1,第二个是2,以此类推,无论它是h2还是h3)。
- 插入锚点:在每个标题标签的内部,自动插入一个带有
name和id属性的<span>标签。这个<span>就是一个锚点,可以被页面内的链接引用。 最终效果: - 原始内容:
<h2>第一章:简介</h2><h3>1.1 背景</h3><h2>第二章:核心内容</h2> - 处理后内容:
<h2><span name="1" id="1"></span>第一章:简介</h2><h3><span name="2" id="2"></span>1.1 背景</h3><h2><span name="3" id="3"></span>第二章:核心内容</h2>
2. 主要用途
此插件是实现**页面内容导航(Table of Contents)**的关键第一步。通过为标题添加唯一的锚点,您可以:
- 在文章顶部自动生成一个可点击的目录列表。
- 用户点击目录中的链接,页面会平滑滚动到对应的标题位置,极大地提升了长篇文章的用户体验。
3. 如何在火车采集器中使用
前提: 您的火车采集器版本需要支持C#脚本处理。 步骤如下:
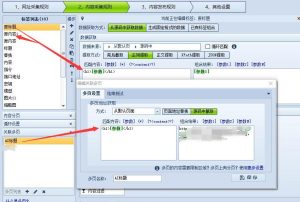
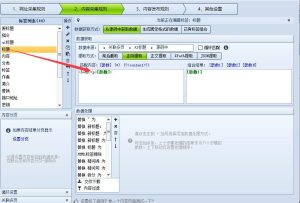
- 复制代码: 将下面提供的完整C#代码复制到火车头C#。
- 进入内容处理规则设置: 在火车采集器中,打开您的任务,进入 “内容规则” 或 “发布模块” 的设置界面。
- 添加C#处理: 在内容处理流程中,找到 “C#处理” 或类似的选项,点击添加。
- 粘贴代码: 在弹出的C#代码编辑框中,将第1步复制的代码粘贴进去。
- 选择处理标签:
- 标签内容:这是最关键的一步。您需要选择一个包含文章正文内容的标签,通常是
内容或body等自定义标签。请确保您选择的是完整的HTML内容,而不是某个字段。 - 不选择标签:如果您选择此项,脚本将处理整个页面的原始HTML,这通常不是您想要的。
- 标签内容:这是最关键的一步。您需要选择一个包含文章正文内容的标签,通常是
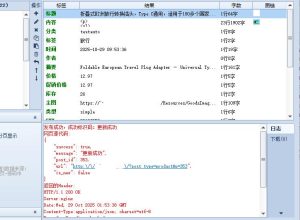
- 保存并测试: 保存您的规则设置。然后运行采集任务,测试一条数据。检查采集到的内容,确认
<h2>和<h3>标签是否已按预期插入了<span name="1" id="1"></span>这样的锚点。
4. 配合生成目录(高级用法)
此脚本只完成了第一步(添加锚点)。要生成可点击的目录,您还需要另一个脚本或处理步骤。 思路:
- 第一步(本脚本):为
<h2>和<h3>添加锚点。 - 第二步(新脚本):
- 再次扫描内容,提取出所有
<h2>和<h3>标签的文本和它们的锚点id。 - 根据这些信息,动态生成一个
<ul>和<li>列表,例如:<ul class="toc"> <li><a href="#1">第一章:简介</a></li> <li><a href="#2">1.1 背景</a></li> <li><a href="#3">第二章:核心内容</a></li> </ul> - 将这个生成的目录HTML插入到文章内容的最前面。 通过这样两步处理,您就可以实现一个完全自动化的、带有可点击目录的文章发布功能。
- 再次扫描内容,提取出所有
5. 注意事项
- 标签顺序:
count变量是连续递增的,它会按照<h2>和<h3>在文章中出现的先后顺序进行编号。 - 兼容性:脚本使用了
RegexOptions.IgnoreCase,可以处理<H2>或<h3>等大小写不规范的标签。 - 性能:对于非常长的文章,正则表达式处理可能会有轻微的性能开销,但对于绝大多数网站文章来说,影响可以忽略不计。
- ID唯一性:由于是顺序编号,在同一篇文章内,生成的锚点
id是唯一的。但如果一页显示多篇文章,可能会有ID冲突的风险,请根据您的网站架构评估。 希望这份详细的说明能帮助您顺利使用这个插件!
© 版权声明
文章版权归作者所有,未经允许请勿转载。
THE END