高铁采集器9.8全功能版,账号密码随意输入,兼容win10。
![图片[1]-高铁采集器9.8全功能版分享下载-SEO模板](https://www.seomoban.cn/wp-content/uploads/2026/03/高铁采集器-300x166.jpg)
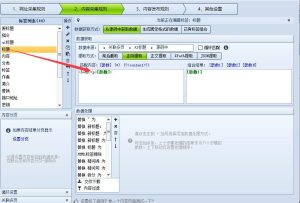
高铁采集器采集规则编写方法
在使用高铁采集器进行数据采集时,有时需要使用正则表达式来提取符合条件的数据。下面我们来简单介绍一下如何编写正则表达式。
1. 正则表达式基础语法
正则表达式又称“正规表示法”、“规则表达式”,是用于描述、匹配一类字符串的表达式。在编写正则表达式时,需要掌握一些常用的语法元素:
(1)字符表示法:使用单个字符表示某种特定意义。例如,正则表达式中的“a”表示匹配单个小写字母“a”。
(2)字符组:使用多个字符集合进行匹配。例如,正则表达式中的“[abcd]”表示匹配字符“a”、“b”、“c”或“d”。
(3)量词:用于描述字符或字符串的匹配次数。例如,正则表达式中的“{n,m}”表示匹配前一个元素至少n个,最多m个。
(4)特殊字符:特殊字符具有特殊的含义,在正则表达式中需要进行转义。例如,正则表达式中的“.?+()*^$|\”等字符都需要使用反斜杠进行转义。
2. 正则表达式编写方法
在高铁采集器中编写正则表达式时,一般需要遵循以下步骤:
(1)了解采集对象:需要先了解所要采集的页面结构和目标数据类型,例如文本、数字、图片等。
(2)查找匹配规律:可以使用浏览器的开发者工具或其他抓包工具查看页面源代码,并根据页面结构和目标数据类型确定匹配规律。
(3)编写正则表达式:根据匹配规律和基础语法元素,编写符合要求的正则表达式。可以使用在线工具进行测试和优化调整。
(4)应用到采集任务中:将编写好的正则表达式应用到采集任务中,并进行测试和调整。
3. 正则表达式案例
以下是一些常见的正则表达式案例,供参考:
(1)匹配数字:\d
(2)匹配字母:[a-zA-Z]
(3)匹配中文字符:[\u4e00-\u9fa5]
(4)匹配邮箱地址:\w+([-+.]\w+)*@\w+([-.]\w+)*\.\w+([-.]\w+)*
(5)匹配URL地址:[a-zA-z]+://[^\\s]*
高铁采集器使用方法
高铁采集器是一款方便易用的数据采集工具,它可以自动抓取互联网上的数据,并将其转换为可用的格式。下面是高铁采集器的使用教程:
1. 安装高铁采集器
首先,您需要下载并安装高铁采集器软件。可以在高铁采集器官方网站下载安装包,根据提示完成安装即可。
2. 新建采集任务
打开高铁采集器软件后,首先需要新建一个采集任务。在界面上单击“新建任务”按钮,输入任务名称和采集网址,然后单击“确认”按钮即可。
3. 设置采集规则
在新建的采集任务中,需要设置采集规则来指导高铁采集器如何抓取数据。在采集器界面上选择“采集规则”选项卡,然后选择要采集的字段,例如标题、正文、图片等。可以使用高铁采集器提供的自动识别规则,也可以手动创建规则。
4. 开始采集
设置好采集规则后,可以点击“立即采集”按钮开始采集数据。高铁采集器会自动访问指定的页面,并根据设定的规则抓取相应的数据。采集过程中还可以设置代理服务器和请求头,以防止被检测为机器人而被封禁。
5. 数据导出
当采集完成后,可以将数据导出为各种文件格式,例如Excel、TXT、JSON等。选择“导出数据”选项卡,选择要导出的数据和文件格式,然后单击“导出”按钮即可将数据保存到本地。
高铁高铁采集器怎么使用数据转换
高铁采集器是一款有用的数据采集工具,它可以自动抓取互联网上的数据,并且在抓取数据后,可以进行数据转换以提高数据的可用性和适用性。
高铁采集器可以将收集到的数据转换为多种不同的格式,并且可以进行数据清理、去重、筛选和分析等操作。在进行数据转换之前,通常需要进行以下几个步骤:
分析采集目标:在进行数据转换之前,需要对采集目标进行仔细分析。这可以帮助您了解采集目标的数据结构和特征,以便更好地处理数据。
设计转换方案:根据采集目标的特征和要求,设计数据转换方案。这包括转换方式、转换格式、源数据结构和目标数据结构等。
转换数据:根据转换方案,进行数据转换。高铁采集器提供了多种转换方式和格式,以便根据需要自由选择和配置。
以下是一些常见的高铁采集器数据转换方式:
格式转换 高铁采集器可以将数据转换为多种格式,例如XML、JSON、CSV等。其中,XML和JSON格式可以轻松地与常用的编程语言相集成,CSV格式比较适合进行数据分析和处理。
数据清洗 在采集过程中,我们可能会面临各种各样的“脏数据”,例如HTML标签、空格和换行符等,这些数据可能会影响数据的可用性和适用性。高铁采集器提供了强大的数据清洗功能,可以将非常规数据清洗干净,让数据更加干净和规整。
数据筛选 在采集数据后,我们需要根据具体目的和要求对数据进行筛选和过滤。高铁采集器可以根据设置的规则和条件进行数据筛选,例如去除重复数据、筛选指定日期范围内的数据等。
高铁采集器任务分组右键功能
高铁采集器是一款实用性强的数据采集工具,它可以自动抓取互联网上的数据,并将其转换为可用的格式。在针对多个网站进行数据采集时,往往需要对相近的任务进行分组管理。此时,高铁采集器的任务分组右键功能十分实用。
新建任务分组 首先,需要在高铁采集器的主界面上创建任务分组。在左侧导航栏中,选择“任务分组”,然后单击“新建分组”按钮,输入分组名称,即可创建一个新的任务分组。
拖拽任务到任务分组 在创建好任务分组之后,可以将相应的采集任务拖拽到对应的分组中。在左侧导航栏中选择“采集任务”,即可看到所有创建的采集任务。将任务拖拽到对应的任务分组,即可将其移动到该分组中。
右键管理任务分组 在分组管理界面中,可以右键单击任务分组,然后选择“任务管理”或“重命名”等选项,以便对分组进行进一步的管理和操作。
批量操作任务 在分组管理界面中,可以选中多个任务,并选择“删除”、“启动”或“停止”等操作,以便批量操作任务的状态和设置。
高铁采集器如何设置起始网址
高铁采集器是一款非常好用的内容采集发布程序,可以帮助用户瞬间建立一个拥有庞大内容的网站。如果你想要设置高铁采集器的起始网址,可以按照以下步骤进行操作:
首先,在软件主页面中添加起始网址,点击“添加”按钮即可。然后,在弹出的页面中,选择批量/多页。接下来,在地址格式设置需要采集的网页链接。最后,点击“完成”按钮即可。
除此之外,高铁采集器还支持远程图片下载、图片批量水印、Flash下载、下载文件地址探测、自制作发表的cms模块参数、自定义发表的内容等有关采集器的内容。同时,对于数据的采集其可以分为两部分,一是采集数据,二是发布数据。
你可以成功设置高铁采集器的起始网址,从而更好地进行内容采集和发布。同时,高铁采集器还有许多其他的功能和特点,例如支持多线程内容采集发布程序、可以瞬间建立一个拥有庞大内容的网站等,非常适合广大用户使用。
高铁采集器设置获取内容网址的方法
1.首先,在高铁采集器中点击“添加”按钮,选择“批量/多页”。
2.在地址格式设置中需要采集的网页链接。
3.点击“完成”按钮即可。
需要注意的是,在设置高铁采集器获取内容网址时,需要根据实际情况进行正确的操作。同时,采集的内容需要符合法律法规和道德规范,不能侵犯他人的合法权益。此外,在进行内容采集时,也需要尊重原创性和版权问题,尽可能地获取授权或许可证,避免侵权纠纷的发生。
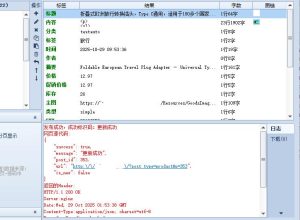
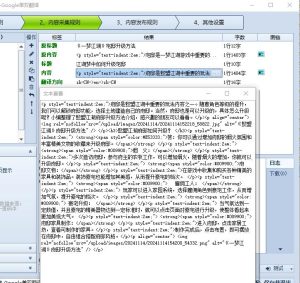
高铁采集器设置标签编辑
首先,在打开高铁采集器后,我们需要选择要设置标签的采集任务。在任务列表中,选择需要设置标签的任务,右键点击,选择“编辑任务”即可进入采集任务编辑页面。
接下来,在左侧的“设置”栏目中,选择“标签设置”选项。在标签设置页面中,可以看到标签列表及其对应的采集字段。我们可以根据需要添加、删除、编辑标签,并将其与相应的采集字段关联起来。
在添加标签的过程中,我们可以根据需要设置标签的名称、标签类型、标签值等参数。其中标签类型包括文本、数字、日期等类型,而标签值则可以根据具体需求自行输入或通过JS代码获取。
在删除标签时,需要注意的是,如果某个标签与多个采集字段关联在一起,则删除该标签可能会影响其他采集字段的正常采集。因此,建议在删除标签前先检查其关联情况,确保不会影响其他采集字段的正常采集。
除了添加、删除、编辑标签外,我们还可以通过拖拽的方式调整标签的显示顺序,以便更好地管理和使用标签。
在设置标签时,还需要注意以下几点:
1. 合理命名:标签的命名应该具有明确的语义,避免出现歧义。例如,“标题”标签应该命名为“article_title”,而不是简单地命名为“title”。
2. 合理分配:采集任务中的每个字段都应该分配合适的标签,以便于统一管理和分类。如果一个字段没有对应的标签,那么它就不会被采集器正常采集。
3. 合理组合:不同的标签可以组合使用,以达到更好的采集效果。例如,在采集网页列表时,可以使用“链接”、“标题”、“描述”等标签组合,从而更全面地采集网页信息。
在标签设置完成后,我们可以点击“保存”按钮保存设置,并按需进行其它相关设置。设置完成后,我们可以运行采集任务进行测试,以确保标签设置的准确性和有效性。
高铁采集器数据处理
高铁采集器数据处理——彻底解决数据管理难题
随着信息化时代的发展,数据处理变得越来越重要。从最初电子表格管理到现在数据采集、分析、清洗、可视化等全方位的数据管理能力,数据处理已经逐渐成为互联网时代最重要的技能之一。而高铁采集器作为一款优秀的数据采集工具,为我们提供了高效便捷的数据采集服务。本文将围绕高铁采集器数据处理展开讲解,助你解决数据管理难题。
高铁采集器是一款数据采集工具,可以用于采集各种数据,并进行加工处理、存储等操作。相对于传统自主开发的数据采集系统,高铁采集器在使用效率和采集质量上有明显优势。采集过程中,高铁采集器借助提供的各种规则进行自动化操作,可以极大地简化数据采集过程,同时通过不断更新匹配规则也保障了采集质量的稳定性。
在数据采集之后,对数据的处理也十分重要。最基本的数据处理可以通过电子表格软件进行操作,但一旦面对大量数据,单纯依赖电子表格进行处理很容易出现问题。因此,采用专业的数据处理软件可以大大提高数据处理的效率和准确性。高铁采集器在这方面同样表现优异。它提供了丰富的数据处理选项,包括文本处理、数据匹配、去重、数据清洗等功能,帮助用户快速高效地处理数据。特别是高铁采集器的文本处理功能,可以将非结构化数据转换成结构化数据,方便用户进行进一步的信息提取和加工。
采集和处理数据只是数据管理的前两个关键步骤,数据存储和分析同样十分重要。高铁采集器也在这方面提供了全面的解决方案。它支持数据导出到多种格式,包括Excel、CSV、JSON等,将数据存储在用户指定的目录里。此外,高铁采集器还支持数据存储在云端,这样能够方便不同团队协同工作,分享数据。
最后,高铁采集器提供的数据分析功能也非常强大。它内置了自动化分析工具,可以分析数据的趋势和规律,并提出有价值的建议。同时,它还支持自定义分析,让用户可以根据自己的需求,进行更深入的数据分析。
高铁采集器内容分页设置的作用
高铁采集器的一大特点就是能够采集大量信息,但是如果要采集的信息太多,就会导致采集速度变慢,甚至无法顺利采集。这时候,设置内容分页就能解决这个问题。内容分页可以将网页内容分成多个部分,让采集器分多次采集,大大提高采集速度。此外,内容分页还可以提高采集效率,减少服务器资源的消耗,避免被封锁。
高铁采集器内容分页的设置方法
要进行内容分页设置,需要先安装高铁采集器,以及搭建好需要采集的网站。接下来,我们将依次介绍设置内容分页的具体步骤。
第一步:打开需要采集的网站,并进入需要采集的页面,将页面的链接复制到高铁采集器。
第二步:在高铁采集器的规则编辑器中,找到需要设置的采集字段,然后点击“高级设置”按钮。
第三步:在高级设置窗口中,找到“内容分页”选项,然后打开。
第四步:根据需要,设置“每页采集条目数”、“内容分页网址规则”等选项。这些选项的具体含义如下:
每页采集条目数:设置每个分页包含的采集条目数量,建议根据网站的情况选择一个比较合适的值,以便提高采集效率。
内容分页网址规则:设置如何对网页进行分页,可以通过正则表达式来匹配不同的网页链接。这部分比较复杂,建议有一定编程经验的用户使用。
第五步:保存设置,然后开始采集。采集器将按照设置的内容分页规则进行采集,直到采集结束为止。
高铁采集器的内容分页设置可以帮助用户更好地采集网页内容,提高采集速度和效率。本文向您介绍了内容分页设置的方法和步骤,可以帮助您更好地使用高铁采集器,将采集的效果发挥到最大。
高铁采集器循环怎么设置
为了使用高铁采集器的循环设置,首先需要下载和安装高铁采集器软件。接着,按照以下步骤进行操作:
1、打开高铁采集器软件,点击左侧的“新建任务”按钮,进入新建任务界面。
2、在新建任务界面,填写需要采集的网站地址和要采集的数据规则。确认无误后,点击“确定”按钮。
3、在任务列表界面,选中新建的任务,然后点击“编辑”按钮。
4、在编辑任务界面,点击左侧的“循环设置”按钮,进入循环设置界面。
5、循环设置界面中,可以设置循环次数、循环时间间隔、循环起始时间等参数。根据实际需求进行设置即可。
6、将设置保存后,返回任务列表界面,点击“启动任务”按钮,开始执行采集任务。任务执行完成后,可以在任务列表中查看采集结果。
通过以上设置,我们可以定期自动采集目标网站的数据。循环设置中的参数可以根据实际需求进行调整,以满足不同的采集需求。
高铁采集器如何设置关联多页
高铁采集器是一款非常强大的网络爬虫工具。它可以在网络上自动采集大量信息,并提供便捷的管理与筛选功能。如果你需要采集的信息分布在多个页面,那么设置关联多页就非常重要了。那么如何使用高铁采集器来设置关联多页呢?本文将为大家进行详细介绍。
第一步:打开高铁采集器并新建项目
首先,我们需要打开高铁采集器并新建一个项目。在主菜单中选择“新建项目”,然后填写项目名称和起始URL。如果你需要采集的信息在某个网站的多页中,请务必将第一页的URL填入起始URL中。
第二步:设置关联多页规则
在新建好项目后,我们需要设置关联多页规则。在项目管理页面,选择“高级选项”标签,找到“关联多页”选项。点击“添加”按钮,然后按照提示信息设置关联多页规则。
通常情况下,你需要填写关联的URL规则。这些规则可以是正则表达式,也可以是通配符模式。例如,如果你需要采集的信息分布在所有页面的URL中都包含“page”关键字的网站上,那么可以在关联规则中填写“*page*”。
除此之外,你还可以设置关联页面的采集模板。这个模板可以帮助你快速采集每个关联页面上的信息。在模板中,你可以使用各种变量和函数来提取需要的信息。如果你不熟悉模板的语法,可以参考高铁采集器的文档或者官方论坛中的相关帖子。
第三步:运行采集任务并检查结果
设置好关联多页规则后,我们需要运行采集任务并检查结果。在任务管理页面,点击“运行”按钮启动采集任务。高铁采集器会自动按照关联规则采集每个关联页面上的信息,并将结果保存到本地数据库中。
完成采集任务后,我们可以对结果进行进一步的处理。在采集管理页面中,选择“数据清洗”标签,然后使用数据清洗器筛选和提取需要的信息。你可以使用各种过滤器和规则来对采集结果进行处理。
相关问题解决: